

Data & Code
RWC 2.0, 2026

Data: Zenodo
Annotations: GitHub
The Real World Computing (RWC) Music Database has been a cornerstone of Music Information Retrieval (MIR) research for over two decades, offering high‑quality recordings across multiple genres, including popular, classical, and jazz music. With RWC 2.0, we aim not only to renew the dataset’s impact and preserve its legacy within the MIR community but also to shed light on broader best practices for open, collaborative, and sustainable research infrastructures.
ChoraleBricks Dataset, 2025

Link: Accompanying Website
In ChoraleBricks, we address this underexplored area by introducing ChoraleBricks, a framework featuring multitrack recordings of ten different chorales, each comprising four musical parts: soprano, alto, tenor, and bass. At its core, ChoraleBricks provides isolated recordings of individual parts performed by a diverse selection of wind instruments, including flute, oboe, clarinet, trumpet, saxophone, baritone, trombone, and tuba. These isolated recordings act as building blocks or "bricks" that can be modularly superimposed to create full mixes with varying instrumentations.
Jazz Structure Dataset (JSD), 2023
Link: GitHub Repository
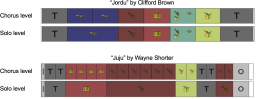
The Jazz Structure Dataset (JSD) comprises structure annotations for 340 famous Jazz recordings. Along with the temporal annotations for song regions (e.g., Solo 1 starting at 40 s and ending at 113 s), it provides further metadata about the predominant instrument (in most cases the soloist) and the accompanying instruments (e.g., drums and piano).
Multiple Predominant Melody Annotations for Jazz Recordings, 2016
Link: Accompanying Website
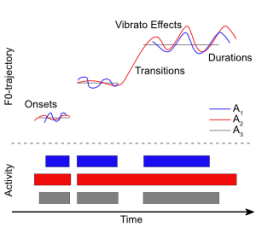
Melody estimation algorithms are typically evaluated by separately assessing the tasks of voice activity detection and fundamental frequency estimation. For both subtasks, computed results are typically compared to a single human reference annotation. This is problematic since different human experts may differ in how they specify a predominant melody, thus leading to a pool of equally valid reference annotations. In this dataset, we address the problem of evaluating melody extraction algorithms within a jazz music scenario.