

Source Separation of Piano Concertos with Test-Time Adaptation
This is the accompanying website for the article Source Separation of Piano Concertos with Test-Time Adaptation.
- Yigitcan Özer and Meinard Müller
Source Separation of Piano Concertos with Test-Time Adaptation
In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR): 493–500, 2022. PDF Presentation@inproceedings{OezerM22_PianoSepAdapt_ISMIR, author = {Yigitcan \"Ozer and Meinard M\"uller}, title = {Source Separation of Piano Concertos with Test-Time Adaptation}, booktitle = {Proceedings of the International Society for Music Information Retrieval Conference ({ISMIR})}, address = {Bengaluru, India}, year = {2022}, pages = {493--500}, url-pdf = {2022_OezerM_PianoSepAdapt_ISMIR_ePrint.pdf}, url-presentation = {2022_OezerM_PianoSepAdapt_ISMIR_poster.pdf} }
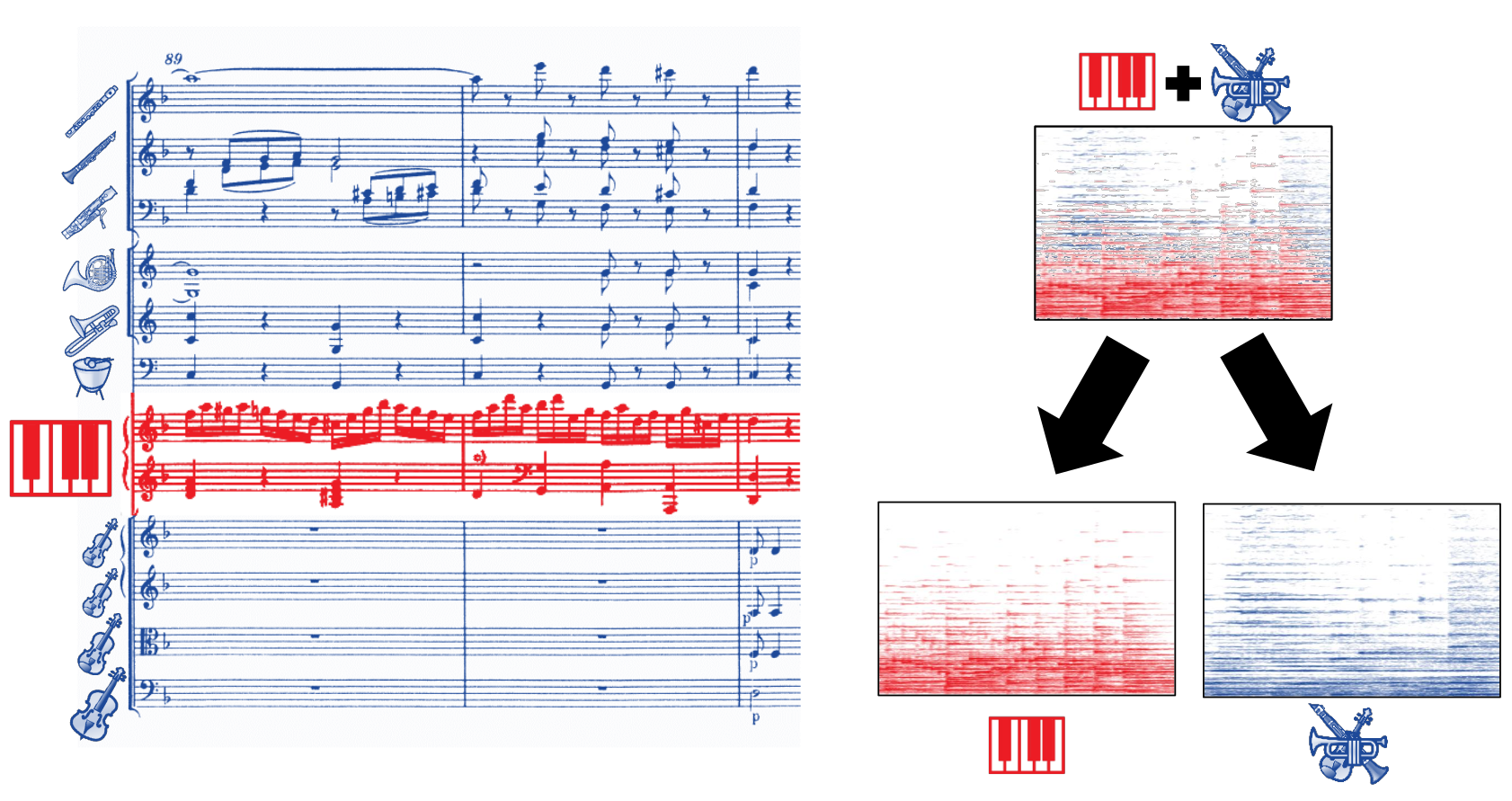
Abstract
Music source separation (MSS) aims at decomposing a music recording into its constituent sources, such as a lead instrument and the accompaniment. Despite the difficulties in MSS due to the high correlation of musical sources in time and frequency, deep neural networks (DNNs) have led to substantial improvements to accomplish this task. For training supervised machine learning models such as DNNs, isolated sources are required. In the case of popular music, one can exploit open-source datasets which involve multitrack recordings of vocals, bass, and drums. For western classical music, however, isolated sources are generally not available. In this article, we consider the case of piano concertos, which is a genre composed for a pianist typically accompanied by an orchestra. The lack of multitrack recordings makes training supervised machine learning models for the separation of piano and orchestra challenging. To overcome this problem, we generate artificial training material by randomly mixing sections of the solo piano repertoire (e.g., piano sonatas) and orchestral pieces without piano (e.g., symphonies) to train state-of-the-art DNN models for MSS. As our main contribution, we propose a test-time adaptation (TTA) procedure, which exploits random mixtures of the piano-only and orchestra-only parts in the test data to further improve the separation quality.
Selected Test Items
| [Beethoven_Op015-01] | [Beethoven_Op037-01] | [Beethoven_Op058-01] | [Brahms_Op015-03] |
| [Haydn_Hob018No011-01-03] | [Mozart_KV466-01] | [Mozart_KV467-01] | [Mozart_KV595-01] |
References
- Ethan Manilow, Patrick O'Reilly, Prem Seetharaman, and Bryan Pardo
Source Separation By Steering Pretrained Music Models
In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2022.@inproceedings{ManilowRSP2022_SepSteeringPretrainedModels_ICASSP, author = {Ethan Manilow and Patrick O'Reilly and Prem Seetharaman and Bryan Pardo}, title = {Source Separation By Steering Pretrained Music Models}, booktitle = {Proceedings of the {IEEE} International Conference on Acoustics, Speech, and Signal Processing ({ICASSP})}, address = {Singapore, Singapore}, year = {2022}, } - Yu Wang, Juan Pablo Bello, Daniel Stoller, and Rachel Bittner
Few-Shot Musical Source Separation
In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2022.@inproceedings{WangBSB2022_FewShotSourceSep_ICASSP, author = {Yu Wang and Juan Pablo Bello and Daniel Stoller and Rachel Bittner}, title = {Few{-}Shot Musical Source Separation}, booktitle = {Proceedings of the {IEEE} International Conference on Acoustics, Speech, and Signal Processing ({ICASSP})}, address = {Singapore, Singapore}, year = {2022}, } - Matteo Torcoli, Thorsten Kastner, and Jürgen Herre
Objective Measures of Perceptual Audio Quality Reviewed: An Evaluation of Their Application Domain Dependence
IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29: 1530–1541, 2021. DOI@article{TorcoliKJ21_ObjectiveMeasures_TALSP, author={Matteo Torcoli and Thorsten Kastner and Jürgen Herre}, journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing}, title={Objective Measures of Perceptual Audio Quality Reviewed: An Evaluation of Their Application Domain Dependence}, year={2021}, volume={29}, pages={1530-1541}, doi={10.1109/TASLP.2021.3069302} } - Alexandre Défossez
Hybrid Spectrogram and Waveform Source Separation
In Proceedings of the ISMIR 2021 Workshop on Music Source Separation, 2021.@inproceedings{Defossez2021_Demucs_ISMIR, title={Hybrid Spectrogram and Waveform Source Separation}, author={Alexandre Défossez}, booktitle={Proceedings of the ISMIR 2021 Workshop on Music Source Separation}, year={2021} } - Ching-Yu Chiu, Wen-Yi Hsiao, Yin-Cheng Yeh, Yi-Hsuan Yang, and Alvin Wen-Yu Su
Mixing-specific data augmentation techniques for improved blind violin/piano source separation
In 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP): 1–6, 2020.@inproceedings{ChiuHYYSA2020_DataAugViolinPianoSeparation_MMSP, title={Mixing-specific data augmentation techniques for improved blind violin/piano source separation}, author={Ching-Yu Chiu and Wen-Yi Hsiao and Yin-Cheng Yeh and Yi-Hsuan Yang and Alvin Wen-Yu Su}, booktitle={2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP)}, pages={1--6}, year={2020}, organization={IEEE} } - Romain Hennequin, Anis Khlif, Felix Voituret, and Manuel Moussallam
Spleeter: A Fast and Efficient Music Source Separation Tool with Pre-trained Models
Journal of Open Source Software, 5(50): 2154, 2020. DOI@article{HennequinKVM2020_Spleeter_JOSS, doi = {10.21105/joss.02154}, url = {https://doi.org/10.21105/joss.02154}, year = {2020}, publisher = {The Open Journal}, volume = {5}, number = {50}, pages = {2154}, author = {Romain Hennequin and Anis Khlif and Felix Voituret and Manuel Moussallam}, title = {Spleeter: A Fast and Efficient Music Source Separation Tool with Pre-trained Models}, journal = {Journal of Open Source Software}, note = {Deezer Research} } - Fabian-Robert Stöter, Stefan Uhlich, Antoine Liutkus, and Yuki Mitsufuji
Open-Unmix — A Reference Implementation for Music Source Separation
Journal of Open Source Software, 4(41), 2019. DOI@article{StoeterULM19_Unmix_JOSS, author = {Fabian{-}Robert St{\"{o}}ter and Stefan Uhlich and Antoine Liutkus and Yuki Mitsufuji}, title = {{Open-Unmix} -- {A} Reference Implementation for Music Source Separation}, journal = {Journal of Open Source Software}, volume = {4}, number = {41}, year = {2019}, url = {https://doi.org/10.21105/joss.01667}, doi = {10.21105/joss.01667} } - Zafar Rafii, Liutkus, Fabian-Robert Stöter, Ioannis Mimilakis, Derry FitzGerald, and Bryan Pardo
An Overview of Lead and Accompaniment Separation in Music
IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(8): 1307–1335, 2018. DOI@article{RafiiLSMFP18_LeadAcc_IEEE, author = {Zafar Rafii and Liutkus and Fabian{-}Robert St{\"{o}}ter and Ioannis Mimilakis and Derry FitzGerald and Bryan Pardo}, title = {An Overview of Lead and Accompaniment Separation in Music}, journal = {{IEEE/ACM} Transactions on Audio, Speech, and Language Processing}, volume = {26}, number = {8}, pages = {1307--1335}, year = {2018}, doi = {10.1109/TASLP.2018.2825440}, }
Acknowledgments
| This work was supported by the German Research Foundation (DFG MU 2686/10-2). The authors are with the International Audio Laboratories Erlangen, a joint institution of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and Fraunhofer Institute for Integrated Circuits IIS. |  |