Data-Driven Solo Voice Enhancement for Jazz Music Retrieval
This is the accompanying website for the paper:
- Stefan Balke, Christian Dittmar, Jakob Abeßer, and Meinard Müller
Data-Driven Solo Voice Enhancement for Jazz Music Retrieval
In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP): 196–200, 2017. PDF Demo Presentation@inproceedings{BalkeDAM17_SoloVoiceEnhancement_ICASSP, author = {Stefan Balke and Christian Dittmar and Jakob Abe{\ss}er and Meinard M{\"u}ller}, title = {Data-Driven Solo Voice Enhancement for Jazz Music Retrieval}, booktitle = {Proceedings of the {IEEE} International Conference on Acoustics, Speech, and Signal Processing ({ICASSP})}, pages = {196--200}, location = {New Orleans, USA}, year = {2017}, url-demo={https://www.audiolabs-erlangen.de/resources/MIR/2017-ICASSP-SoloVoiceEnhancement}, url-pdf = {2017_BalkeDAM_SoloVoiceEnhancement_ICASSP.pdf}, url-presentation = {2017_BalkeDAM_SoloVoiceEnhancement_ICASSP_presentation.pdf} }
Abstract
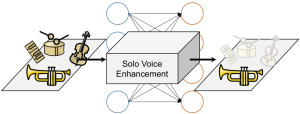
Retrieving short monophonic queries in music recordings is a challenging research problem in Music Information Retrieval (MIR). In jazz music, given a solo transcription, one retrieval task is to find the corresponding (potentially polyphonic) recording in a music collection. Many conventional systems approach such retrieval tasks by first extracting the predominant F0-trajectory from the recording, then quantizing the extracted trajectory to musical pitches and finally comparing the resulting pitch sequence to the monophonic query. In this paper, we introduce a data-driven approach that avoids the hard decisions involved in conventional approaches: Given pairs of time-frequency (TF) representations of full music recordings and TF representations of solo transcriptions, we use a DNN-based approach to learn a mapping for transforming a "polyphonic" TF representation into a "monophonic" TF representation. This transform can be considered as a kind of solo voice enhancement. We evaluate our approach within a jazz solo retrieval scenario and compare it to a state-of-the-art method for predominant melody extraction.
Data and Trained Models
Our used data is available upon request (stefan.balke@audiolabs-erlangen.de, 10 folds, see paper for details, ca. 3 GB, contains compressed numpy arrays).
On each fold, we train a DNN using keras (v. 1.0.5).
Model specifications, trained weights and biases are available for download here (ca. 1 MB, h5 and json files).
Examples
Please activate the player to start playback. Use the slider to mix between the audio recording and the input processed output features for the DNN.
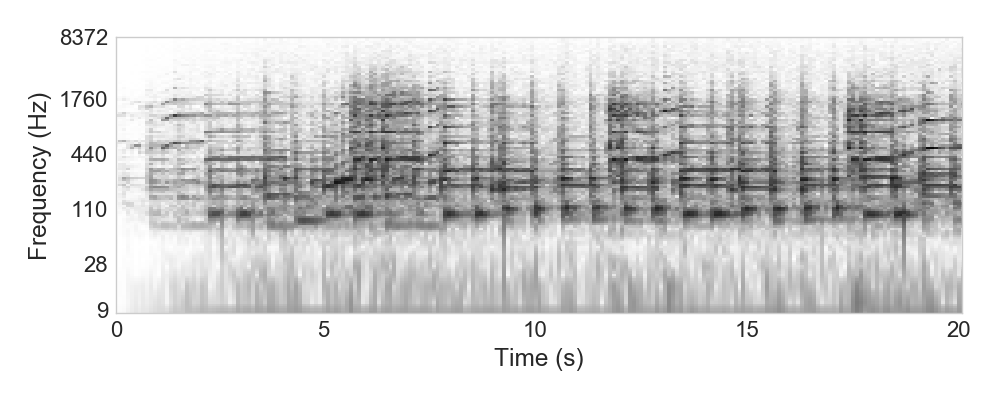
Example: Clifford Brown - Jordu

Example: John Coltrane - Blue Train

Example: Curtis Fuller - Blue Train
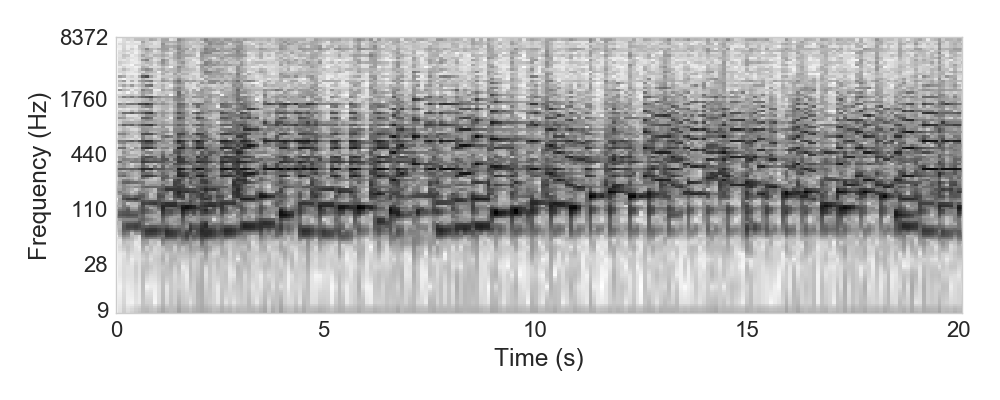
Example: Sidney Bechet - Summertime